
3.2 Keras简介
本书的代码示例全都使用 Keras实现。Keras是一个 Python深度学习框架,可以方便地定义和训练几乎所有类型的深度学习模型。 Keras最开始是为研究人员开发的,其目的在于快速实验。
Keras具有以下重要特性。
- 相同的代码可以在 CPU或 GPU上无缝切换运行。
- 具有用户友好的 API,便于快速开发深度学习模型的原型。
- 内置支持卷积网络(用于计算机视觉)、循环网络(用于序列处理)以及二者的任意组合。
- 支持任意网络架构:多输入或多输出模型、层共享、模型共享等。这也就是说, Keras能够构建任意深度学习模型,无论是生成式对抗网络还是神经图灵机。
Keras基于宽松的 MIT许可证发布,这意味着可以在商业项目中免费使用它。它与所有版本的 Python都兼容(截至 2017年年中,从 Python 2.7到 Python 3.6都兼容)。
Keras已有 200 000多个用户,既包括创业公司和大公司的学术研究人员和工程师,也包括研究生和业余爱好者。Google、Netflix、Uber、CERN、Yelp、Square以及上百家创业公司都在用 Keras解决各种各样的问题。 Keras还是机器学习竞赛网站 Kaggle上的热门框架,最新的深度学习竞赛中,几乎所有的优胜者用的都是 Keras模型,如图 3-2所示。
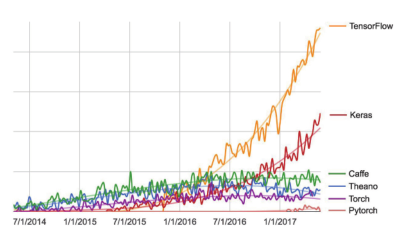
图 3-2 不同深度学习框架的 Google网页搜索热度的变化趋势
3.2.1 Keras、TensorFlow、Theano和 CNTK
Keras是一个模型级(model-level)的库,为开发深度学习模型提供了高层次的构建模块。它不处理张量操作、求微分等低层次的运算。相反,它依赖于一个专门的、高度优化的张量库来完成这些运算,这个张量库就是 Keras的后端引擎(backend engine)。Keras没有选择单个张量库并将 Keras实现与这个库绑定,而是以模块化的方式处理这个问题(见图 3-3)。因此,几个不同的后端引擎都可以无缝嵌入到 Keras中。目前,Keras有三个后端实现:TensorFlow后端、Theano后端和微软认知工具包(CNTK,Microsoft cognitive toolkit)后端。未来 Keras可能会扩展到支持更多的深度学习引擎。
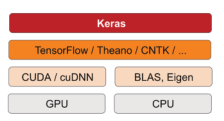
图 3-3 深度学习的软件栈和硬件栈
TensorFlow、CNTK和 Theano是当今深度学习的几个主要平台。Theano由蒙特利尔大学的MILA实验室开发,TensorFlow由 Google开发,CNTK由微软开发。你用 Keras写的每一段代码都可以在这三个后端上运行,无须任何修改。也就是说,你在开发过程中可以在两个后端之间无缝切换,这通常是很有用的。例如,对于特定任务,某个后端的速度更快,那么我们就可以无缝切换过去。我们推荐使用 TensorFlow后端作为大部分深度学习任务的默认后端,因为它的应用最广泛,可扩展,而且可用于生产环境。
通过 TensorFlow(或 Theano、CNTK),Keras可以在 CPU和 GPU上无缝运行。在 CPU上运行时,TensorFlow本身封装了一个低层次的张量运算库,叫作 Eigen;在 GPU上运行时,TensorFlow封装了一个高度优化的深度学习运算库,叫作 NVIDIA CUDA深度神经网络库(cuDNN)。
3.2.2 使用 Keras开发:概述
你已经见过一个 Keras模型的示例,就是 MNIST的例子。典型的 Keras工作流程就和那个例子类似。
(1)定义训练数据:输入张量和目标张量。
(2)定义层组成的网络(或模型),将输入映射到目标。
(3)配置学习过程:选择损失函数、优化器和需要监控的指标。
(4)调用模型的fit方法在训练数据上进行迭代。
定义模型有两种方法:一种是使用 Sequential类(仅用于层的线性堆叠,这是目前最常见的网络架构),另一种是函数式 API(functional API,用于层组成的有向无环图,让你可以构建任意形式的架构)。
前面讲过,这是一个利用 Sequential类定义的两层模型(注意,我们向第一层传入了输入数据的预期形状)。
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(32, activation='relu', input_shape=(784,))) model.add(layers.Dense(10, activation='softmax'))
下面是用函数式 API定义的相同模型。
input_tensor = layers.Input(shape=(784,)) x = layers.Dense(32, activation='relu')(input_tensor) output_tensor = layers.Dense(10, activation='softmax')(x) model = models.Model(inputs=input_tensor, outputs=output_tensor)
利用函数式 API,你可以操纵模型处理的数据张量,并将层应用于这个张量,就好像这些层是函数一样。
注意 第 7章有关于函数式 API的详细指南。在那之前,我们的代码示例中只会用到Sequential类。
一旦定义好了模型架构,使用 Sequential模型还是函数式 API就不重要了。接下来的步骤都是相同的。配置学习过程是在编译这一步,你需要指定模型使用的优化器和损失函数,以及训练过程中想要监控的指标。下面是单一损失函数的例子,这也是目前最常见的。
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='mse',
metrics=['accuracy'])
最后,学习过程就是通过 fit()方法将输入数据的 Numpy数组(和对应的目标数据)传入模型,这一做法与 Scikit-Learn及其他机器学习库类似。
model.fit(input_tensor, target_tensor, batch_size=128, epochs=10)
在接下来的几章里,你将会在这些问题上培养可靠的直觉:哪种类型的网络架构适合解决哪种类型的问题?如何选择正确的学习配置?如何调节模型使其给出你想要的结果?我们将在3.4~3.6节讲解三个基本示例,分别是二分类问题、多分类问题和回归问题。
评论已关闭。