5.2 在小型数据集上从头开始训练一个卷积神经网络
使用很少的数据来训练一个图像分类模型,这是很常见的情况,如果你要从事计算机视觉方面的职业,很可能会在实践中遇到这种情况。“很少的”样本可能是几百张图像,也可能是几万张图像。来看一个实例,我们将重点讨论猫狗图像分类,数据集中包含 4000张猫和狗的图像(2000张猫的图像,2000张狗的图像)。我们将 2000张图像用于训练,1000张用于验证,1000张用于测试。
本节将介绍解决这一问题的基本策略,即使用已有的少量数据从头开始训练一个新模型。首先,在 2000个训练样本上训练一个简单的小型卷积神经网络,不做任何正则化,为模型目标设定一个基准。这会得到 71%的分类精度。此时主要的问题在于过拟合。然后,我们会介绍数据增强(data augmentation),它在计算机视觉领域是一种非常强大的降低过拟合的技术。使用数据增强之后,网络精度将提高到 82%。
5.3节会介绍将深度学习应用于小型数据集的另外两个重要技巧:用预训练的网络做特征提取(得到的精度范围在 90%~96%),对预训练的网络进行微调(最终精度为 97%)。总而言之,这三种策略——从头开始训练一个小型模型、使用预训练的网络做特征提取、对预训练的网络进行微调——构成了你的工具箱,未来可用于解决小型数据集的图像分类问题。
5.2.1 深度学习与小数据问题的相关性
有时你会听人说,仅在有大量数据可用时,深度学习才有效。这种说法部分正确:深度学习的一个基本特性就是能够独立地在训练数据中找到有趣的特征,无须人为的特征工程,而这只在拥有大量训练样本时才能实现。对于输入样本的维度非常高(比如图像)的问题尤其如此。
但对于初学者来说,所谓“大量”样本是相对的,即相对于你所要训练网络的大小和深度而言。只用几十个样本训练卷积神经网络就解决一个复杂问题是不可能的,但如果模型很小,并做了很好的正则化,同时任务非常简单,那么几百个样本可能就足够了。由于卷积神经网络学到的是局部的、平移不变的特征,它对于感知问题可以高效地利用数据。虽然数据相对较少,但在非常小的图像数据集上从头开始训练一个卷积神经网络,仍然可以得到不错的结果,而且无须任何自定义的特征工程。本节你将看到其效果。
此外,深度学习模型本质上具有高度的可复用性,比如,已有一个在大规模数据集上训练的图像分类模型或语音转文本模型,你只需做很小的修改就能将其复用于完全不同的问题。特别是在计算机视觉领域,许多预训练的模型(通常都是在 ImageNet数据集上训练得到的)现在都可以公开下载,并可以用于在数据很少的情况下构建强大的视觉模型。这是 5.3节的内容。我们先来看一下数据。
5.2.2 下载数据
本节用到的猫狗分类数据集不包含在 Keras中。它由 Kaggle在 2013年末公开并作为一项计算视觉竞赛的一部分,当时卷积神经网络还不是主流算法。你可以从 https://www.kaggle.com/c/dogs-vs-cats/data下载原始数据集(如果没有 Kaggle账号的话,你需要注册一个,别担心,很简单)。
这些图像都是中等分辨率的彩色 JPEG图像。图 5-8给出了一些样本示例。

图 5-8 猫狗分类数据集的一些样本。没有修改尺寸:样本在尺寸、外观等方面是不一样的
不出所料,2013年的猫狗分类 Kaggle竞赛的优胜者使用的是卷积神经网络。最佳结果达到了 95%的精度。本例中,虽然你只在不到参赛选手所用的 10%的数据上训练模型,但结果也和这个精度相当接近(见下一节)。
这个数据集包含 25 000张猫狗图像(每个类别都有 12 500张),大小为 543MB(压缩后)。下载数据并解压之后,你需要创建一个新数据集,其中包含三个子集:每个类别各 1000个样本的训练集、每个类别各 500个样本的验证集和每个类别各 500个样本的测试集。
创建新数据集的代码如下所示。
代码清单 5-4 将图像复制到训练、验证和测试的目录


我们来检查一下,看看每个分组(训练 /验证 /测试)中分别包含多少张图像。
>>> print('total training cat images:', len(os.listdir(train_cats_dir)))
total training cat images: 1000
>>> print('total training dog images:', len(os.listdir(train_dogs_dir)))
total training dog images: 1000
>>> print('total validation cat images:', len(os.listdir(validation_cats_dir)))
total validation cat images: 500
>>> print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
total validation dog images: 500
>>> print('total test cat images:', len(os.listdir(test_cats_dir)))
total test cat images: 500
>>> print('total test dog images:', len(os.listdir(test_dogs_dir)))
total test dog images: 500
所以我们的确有 2000张训练图像、1000张验证图像和 1000张测试图像。每个分组中两个类别的样本数相同,这是一个平衡的二分类问题,分类精度可作为衡量成功的指标。
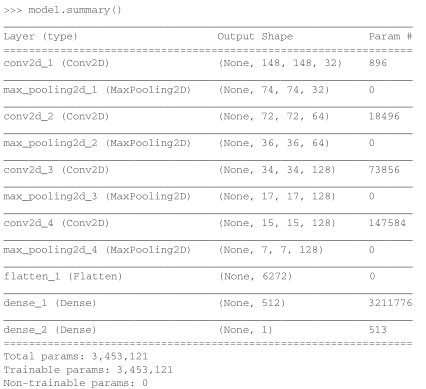
5.2.3 构建网络
在前一个 MNIST示例中,我们构建了一个小型卷积神经网络,所以你应该已经熟悉这种网络。我们将复用相同的总体结构,即卷积神经网络由 Conv2D层(使用 relu激活)和MaxPooling2D层交替堆叠构成。
但由于这里要处理的是更大的图像和更复杂的问题,你需要相应地增大网络,即再增加一个Conv2D+MaxPooling2D的组合。这既可以增大网络容量,也可以进一步减小特征图的尺寸,使其在连接 Flatten层时尺寸不会太大。本例中初始输入的尺寸为 150×150(有些随意的选择),所以最后在Flatten层之前的特征图大小为 7×7。
注意
网络中特征图的深度在逐渐增大(从 32增大到 128),而特征图的尺寸在逐渐减小(从150×150减小到 7×7)。这几乎是所有卷积神经网络的模式。
你面对的是一个二分类问题,所以网络最后一层是使用 sigmoid激活的单一单元(大小为1的Dense层)。这个单元将对某个类别的概率进行编码。
代码清单 5-5 将猫狗分类的小型卷积神经网络实例化
from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))
我们来看一下特征图的维度如何随着每层变化。
在编译这一步,和前面一样,我们将使用RMSprop优化器。因为网络最后一层是单一 sigmoid单元,所以我们将使用二元交叉熵作为损失函数(提醒一下,表 4-1列出了各种情况下应该使用的损失函数)。
代码清单 5-6 配置模型用于训练
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
5.2.4 数据预处理
你现在已经知道,将数据输入神经网络之前,应该将数据格式化为经过预处理的浮点数张量。现在,数据以 JPEG文件的形式保存在硬盘中,所以数据预处理步骤大致如下。
(1)读取图像文件。
(2)将 JPEG文件解码为 RGB像素网格。
(3)将这些像素网格转换为浮点数张量。
(4)将像素值(0~255范围内)缩放到 [0, 1]区间(正如你所知,神经网络喜欢处理较小的输入值)。
这些步骤可能看起来有点吓人,但幸运的是, Keras拥有自动完成这些步骤的工具。 Keras有一个图像处理辅助工具的模块,位于keras.preprocessing.image。特别地,它包含ImageDataGenerator类,可以快速创建 Python生成器,能够将硬盘上的图像文件自动转换为预处理好的张量批量。下面我们将用到这个类。
代码清单 5-7 使用ImageDataGenerator从目录中读取图像

理解 Python生成器
Python生成器(Python generator)是一个类似于迭代器的对象,一个可以和 for …in运算符一起使用的对象。生成器是用yield运算符来构造的。
下面一个生成器的例子,可以生成整数。
def generator():
i=0
while True:
i += 1
yield i
for item in generator():
print(item)
if item > 4:
break
输出结果如下。
1 2 3 4 5
我们来看一下其中一个生成器的输出:它生成了 150×150的 RGB图像[形状为 (20,150, 150, 3)]与二进制标签[形状为(20,)]组成的批量。每个批量中包含 20个样本(批量大小)。注意,生成器会不停地生成这些批量,它会不断循环目标文件夹中的图像。因此,你需要在某个时刻终止(break)迭代循环。

利用生成器,我们让模型对数据进行拟合。我们将使用 fit_generator方法来拟合,它在数据生成器上的效果和fit相同。它的第一个参数应该是一个 Python生成器,可以不停地生成输入和目标组成的批量,比如train_generator。因为数据是不断生成的,所以 Keras模型要知道每一轮需要从生成器中抽取多少个样本。这是steps_per_epoch参数的作用:从生成器中抽取steps_per_epoch个批量后(即运行了steps_per_epoch次梯度下降),拟合过程将进入下一个轮次。本例中,每个批量包含 20个样本,所以读取完所有 2000个样本需要 100个批量。
使用fit_generator时,你可以传入一个 validation_data参数,其作用和在 fit方法中类似。值得注意的是,这个参数可以是一个数据生成器,但也可以是 Numpy数组组成的元组。如果向validation_data传入一个生成器,那么这个生成器应该能够不停地生成验证数据批量,因此你还需要指定validation_steps参数,说明需要从验证生成器中抽取多少个批次用于评估。
代码清单 5-8 利用批量生成器拟合模型
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
始终在训练完成后保存模型,这是一种良好实践。
代码清单 5-9 保存模型
model.save('cats_and_dogs_small_1.h5')
我们来分别绘制训练过程中模型在训练数据和验证数据上的损失和精度(见图 5-9和图 5-10)。
代码清单 5-10 绘制训练过程中的损失曲线和精度曲线
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
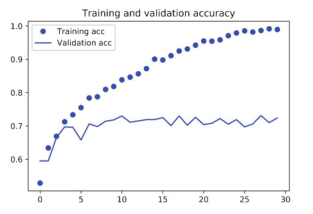
图 5-9 训练精度和验证精度
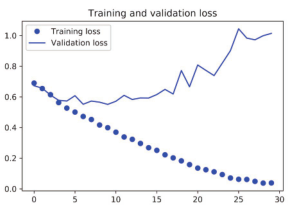
图 5-10 训练损失和验证损失
从这些图像中都能看出过拟合的特征。训练精度随着时间线性增加,直到接近 100%,而验证精度则停留在 70%~72%。验证损失仅在 5轮后就达到最小值,然后保持不变,而训练损失则一直线性下降,直到接近于 0。
因为训练样本相对较少( 2000个),所以过拟合是你最关心的问题。前面已经介绍过几种降低过拟合的技巧,比如 dropout和权重衰减( L2正则化)。现在我们将使用一种针对于计算机视觉领域的新方法,在用深度学习模型处理图像时几乎都会用到这种方法,它就是数据增强(data augmentation)。
5.2.5 使用数据增强
过拟合的原因是学习样本太少,导致无法训练出能够泛化到新数据的模型。如果拥有无限的数据,那么模型能够观察到数据分布的所有内容,这样就永远不会过拟合。数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加(augment)样本。其目标是,模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力。
在 Keras中,这可以通过对ImageDataGenerator实例读取的图像执行多次随机变换来实现。我们先来看一个例子。
代码清单 5-11 利用ImageDataGenerator来设置数据增强
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
这里只选择了几个参数(想了解更多参数,请查阅 Keras文档)。我们来快速介绍一下这些参数的含义。
- rotation_range是角度值(在 0~180范围内),表示图像随机旋转的角度范围。
- width_shift和height_shift是图像在水平或垂直方向上平移的范围(相对于总宽度或总高度的比例)。
- shear_range是随机错切变换的角度。
- zoom_range是图像随机缩放的范围。
- horizontal_flip是随机将一半图像水平翻转。如果没有水平不对称的假设(比如真实世界的图像),这种做法是有意义的。
- fill_mode是用于填充新创建像素的方法,这些新像素可能来自于旋转或宽度/高度平移。
我们来看一下增强后的图像(见图 5-11)。

图 5-11 通过随机数据增强生成的猫图像
代码清单 5-12 显示几个随机增强后的训练图像


如果你使用这种数据增强来训练一个新网络,那么网络将不会两次看到同样的输入。但网络看到的输入仍然是高度相关的,因为这些输入都来自于少量的原始图像。你无法生成新信息,而只能混合现有信息。因此,这种方法可能不足以完全消除过拟合。为了进一步降低过拟合,你还需要向模型中添加一个Dropout层,添加到密集连接分类器之前。
代码清单 5-13 定义一个包含 dropout的新卷积神经网络
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
我们来训练这个使用了数据增强和 dropout 的网络。
代码清单 5-14 利用数据增强生成器训练卷积神经网络
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)

我们把模型保存下来,你会在 5.4节用到它。
代码清单 5-15 保存模型
model.save('cats_and_dogs_small_2.h5')
我们再次绘制结果(见图 5-12和图 5-13)。使用了数据增强和 dropout之后,模型不再过拟合:训练曲线紧紧跟随着验证曲线。现在的精度为 82%,比未正则化的模型提高了 15%(相对比例)。
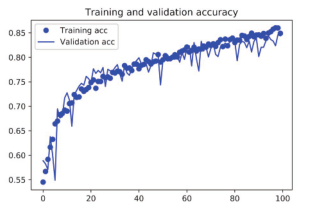
图 5-12 采用数据增强后的训练精度和验证精度
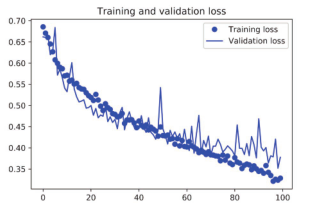
图 5-13 采用数据增强后的训练损失和验证损失
通过进一步使用正则化方法以及调节网络参数(比如每个卷积层的过滤器个数或网络中的层数),你可以得到更高的精度,可以达到86%或87%。但只靠从头开始训练自己的卷积神经网络,再想提高精度就十分困难,因为可用的数据太少。想要在这个问题上进一步提高精度,下一步需要使用预训练的模型,这是接下来两节的重点。