5.4 卷积神经网络的可视化
人们常说,深度学习模型是“黑盒”,即模型学到的表示很难用人类可以理解的方式来提取和呈现。虽然对于某些类型的深度学习模型来说,这种说法部分正确,但对卷积神经网络来说绝对不是这样。卷积神经网络学到的表示非常适合可视化,很大程度上是因为它们是视觉概念的表示。自 2013年以来,人们开发了多种技术来对这些表示进行可视化和解释。我们不会在书中全部介绍,但会介绍三种最容易理解也最有用的方法。
- 可视化卷积神经网络的中间输出(中间激活):有助于理解卷积神经网络连续的层如何对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义。
- 可视化卷积神经网络的过滤器:有助于精确理解卷积神经网络中每个过滤器容易接受的视觉模式或视觉概念。
- 可视化图像中类激活的热力图:有助于理解图像的哪个部分被识别为属于某个类别,从而可以定位图像中的物体。
对于第一种方法(即激活的可视化),我们将使用 5.2节在猫狗分类问题上从头开始训练的小型卷积神经网络。对于另外两种可视化方法,我们将使用 5.3节介绍的 VGG16模型。
5.4.1 可视化中间激活
可视化中间激活,是指对于给定输入,展示网络中各个卷积层和池化层输出的特征图(层的输出通常被称为该层的激活,即激活函数的输出)。这让我们可以看到输入如何被分解为网络学到的不同过滤器。我们希望在三个维度对特征图进行可视化:宽度、高度和深度(通道)。每个通道都对应相对独立的特征,所以将这些特征图可视化的正确方法是将每个通道的内容分别绘制成二维图像。我们首先来加载 5.2节保存的模型。

接下来,我们需要一张输入图像,即一张猫的图像,它不属于网络的训练图像。
代码清单 5-25 预处理单张图像

我们来显示这张图像(见图 5-24)。
代码清单 5-26 显示测试图像
import matplotlib.pyplot as plt plt.imshow(img_tensor[0]) plt.show()
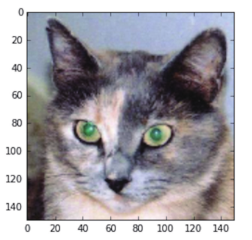
图 5-24 测试的猫图像
为了提取想要查看的特征图,我们需要创建一个 Keras模型,以图像批量作为输入,并输出所有卷积层和池化层的激活。为此,我们需要使用 Keras的Model类。模型实例化需要两个参数:一个输入张量(或输入张量的列表)和一个输出张量(或输出张量的列表)。得到的类是一个Keras模型,就像你熟悉的Sequential模型一样,将特定输入映射为特定输出。Model类允许模型有多个输出,这一点与Sequential模型不同。想了解Model类的更多信息,请参见 7.1节。
代码清单 5-27 用一个输入张量和一个输出张量列表将模型实例化

输入一张图像,这个模型将返回原始模型前 8层的激活值。这是你在本书中第一次遇到的多输出模型,之前的模型都是只有一个输入和一个输出。一般情况下,模型可以有任意个输入和输出。这个模型有一个输入和 8个输出,即每层激活对应一个输出。
代码清单 5-28 以预测模式运行模型

它是大小为 148×148的特征图,有 32个通道。我们来绘制原始模型第一层激活的第 4个通道(见图 5-25)。
代码清单 5-29 将第 4个通道可视化
import matplotlib.pyplot as plt plt.matshow(first_layer_activation[0, :, :, 4], cmap='viridis')
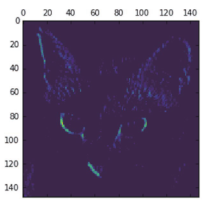
图 5-25 对于测试的猫图像,第一层激活的第 4个通道
这个通道似乎是对角边缘检测器。我们再看一下第 7个通道(见图 5-26)。但请注意,你的通道可能与此不同,因为卷积层学到的过滤器并不是确定的。
代码清单 5-30 将第 7个通道可视化
plt.matshow(first_layer_activation[0, :, :, 7], cmap='viridis')

图 5-26 对于测试的猫图像,第一层激活的第 7个通道
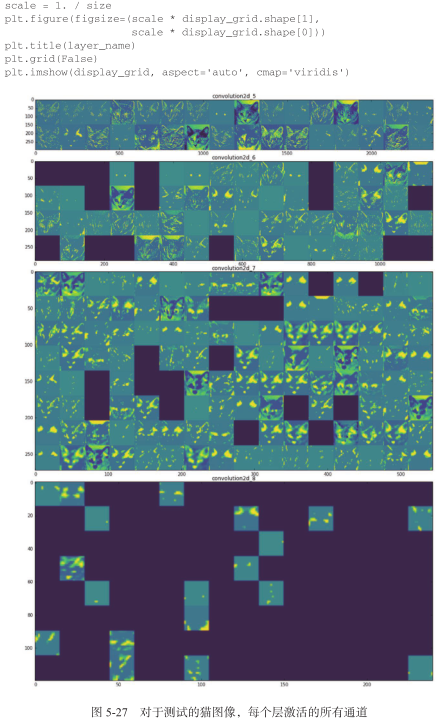
这个通道看起来像是“鲜绿色圆点”检测器,对寻找猫眼睛很有用。下面我们来绘制网络中所有激活的完整可视化(见图 5-27)。我们需要在 8个特征图中的每一个中提取并绘制每一个通道,然后将结果叠加在一个大的图像张量中,按通道并排。
代码清单 5-31 将每个中间激活的所有通道可视化

这里需要注意以下几点。
- 第一层是各种边缘探测器的集合。在这一阶段,激活几乎保留了原始图像中的所有信息。
- 随着层数的加深,激活变得越来越抽象,并且越来越难以直观地理解。它们开始表示更高层次的概念,比如“猫耳朵”和“猫眼睛”。层数越深,其表示中关于图像视觉内容的信息就越少,而关于类别的信息就越多。
- 激活的稀疏度(sparsity)随着层数的加深而增大。在第一层里,所有过滤器都被输入图像激活,但在后面的层里,越来越多的过滤器是空白的。也就是说,输入图像中找不到这些过滤器所编码的模式。
我们刚刚揭示了深度神经网络学到的表示的一个重要普遍特征:随着层数的加深,层所提取的特征变得越来越抽象。更高的层激活包含关于特定输入的信息越来越少,而关于目标的信息越来越多(本例中即图像的类别:猫或狗)。深度神经网络可以有效地作为信息蒸馏管道(information distillation pipeline),输入原始数据(本例中是 RGB图像),反复对其进行变换,将无关信息过滤掉(比如图像的具体外观),并放大和细化有用的信息(比如图像的类别)。
这与人类和动物感知世界的方式类似:人类观察一个场景几秒钟后,可以记住其中有哪些抽象物体(比如自行车、树),但记不住这些物体的具体外观。事实上,如果你试着凭记忆画一辆普通自行车,那么很可能完全画不出真实的样子,虽然你一生中见过上千辆自行车(见图 5-28)。你可以现在就试着画一下,这个说法绝对是真实的。你的大脑已经学会将视觉输入完全抽象化,即将其转换为更高层次的视觉概念,同时过滤掉不相关的视觉细节,这使得大脑很难记住周围事物的外观。
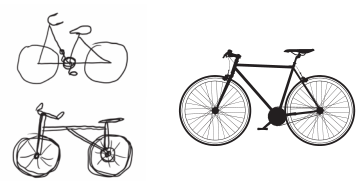
图 5-28 (左图)试着凭记忆画一辆自行车;(右图)自行车示意图
5.4.2 可视化卷积神经网络的过滤器
想要观察卷积神经网络学到的过滤器,另一种简单的方法是显示每个过滤器所响应的视觉模式。这可以通过在输入空间中进行梯度上升来实现:从空白输入图像开始,将梯度下降应用于卷积神经网络输入图像的值,其目的是让某个过滤器的响应最大化。得到的输入图像是选定过滤器具有最大响应的图像。
这个过程很简单:我们需要构建一个损失函数,其目的是让某个卷积层的某个过滤器的值最大化;然后,我们要使用随机梯度下降来调节输入图像的值,以便让这个激活值最大化。例如,对于在ImageNet上预训练的VGG16网络,其block3_conv1层第0个过滤器激活的损失如下所示。
代码清单 5-32 为过滤器的可视化定义损失张量
from keras.applications import VGG16
from keras import backend as K
model = VGG16(weights='imagenet',
include_top=False)
layer_name = 'block3_conv1'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
为了实现梯度下降,我们需要得到损失相对于模型输入的梯度。为此,我们需要使用 Keras的backend模块内置的gradients 函数。
代码清单 5-33 获取损失相对于输入的梯度
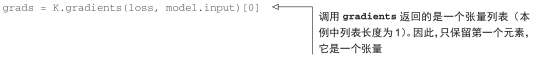
为了让梯度下降过程顺利进行,一个非显而易见的技巧是将梯度张量除以其 L2范数(张量中所有值的平方的平均值的平方根)来标准化。这就确保了输入图像的更新大小始终位于相同的范围。
代码清单 5-34 梯度标准化技巧
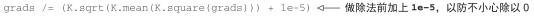
现在你需要一种方法:给定输入图像,它能够计算损失张量和梯度张量的值。你可以定义一个 Keras后端函数来实现此方法:iterate是一个函数,它将一个 Numpy张量(表示为长度为 1的张量列表)转换为两个 Numpy张量组成的列表,这两个张量分别是损失值和梯度值。
代码清单 5-35 给定 Numpy输入值,得到 Numpy输出值
iterate = K.function([model.input], [loss, grads]) import numpy as np loss_value, grads_value = iterate([np.zeros((1, 150, 150, 3))])
现在你可以定义一个 Python循环来进行随机梯度下降。
代码清单 5-36 通过随机梯度下降让损失最大化


得到的图像张量是形状为(1, 150, 150, 3)的浮点数张量,其取值可能不是 [0, 255]区间内的整数。因此,你需要对这个张量进行后处理,将其转换为可显示的图像。下面这个简单的实用函数可以做到这一点。
代码清单 5-37 将张量转换为有效图像的实用函数

接下来,我们将上述代码片段放到一个Python函数中,输入一个层的名称和一个过滤器索引,它将返回一个有效的图像张量,表示能够将特定过滤器的激活最大化的模式。
代码清单 5-38 生成过滤器可视化的函数

我们来试用一下这个函数(见图 5-29)。
>>> plt.imshow(generate_pattern('block3_conv1', 0))
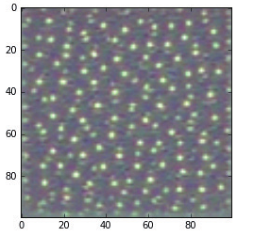
图 5-29 block3_conv1层第 0个通道具有最大响应的模式
看起来,block3_conv1层第 0个过滤器响应的是波尔卡点( polka-dot)图案。下面来看有趣的部分:我们可以将每一层的每个过滤器都可视化。为了简单起见,我们只查看每一层的前 64个过滤器,并只查看每个卷积块的第一层(即 block1_conv1、block2_conv1、block3_conv1、block4_ conv1、block5_conv1)。我们将输出放在一个 8×8的网格中,每个网格是一个 64像素× 64像素的过滤器模式,两个过滤器模式之间留有一些黑边(见图 5-30 ~图 5-33)。
代码清单 5-39 生成某一层中所有过滤器响应模式组成的网格

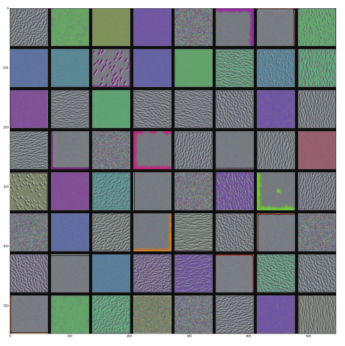
图 5-30 block1_conv1层的过滤器模式
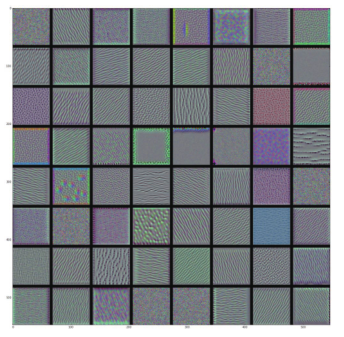
图 5-31 block2_conv1层的过滤器模式
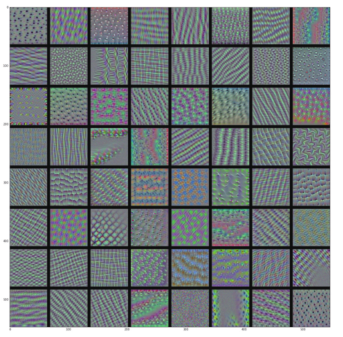
图 5-32 block3_conv1层的过滤器模式

图 5-33 block4_conv1层的过滤器模式
这些过滤器可视化包含卷积神经网络的层如何观察世界的很多信息:卷积神经网络中每一层都学习一组过滤器,以便将其输入表示为过滤器的组合。这类似于傅里叶变换将信号分解为一组余弦函数的过程。随着层数的加深,卷积神经网络中的过滤器变得越来越复杂,越来越精细。
- 模型第一层(block1_conv1)的过滤器对应简单的方向边缘和颜色(还有一些是彩色边缘)。
- block2_conv1层的过滤器对应边缘和颜色组合而成的简单纹理。
- 更高层的过滤器类似于自然图像中的纹理:羽毛、眼睛、树叶等。
5.4.3 可视化类激活的热力图
我还要介绍另一种可视化方法,它有助于了解一张图像的哪一部分让卷积神经网络做出了最终的分类决策。这有助于对卷积神经网络的决策过程进行调试,特别是出现分类错误的情况下。这种方法还可以定位图像中的特定目标。
这种通用的技术叫作类激活图(CAM,class activation map)可视化,它是指对输入图像生成类激活的热力图。类激活热力图是与特定输出类别相关的二维分数网格,对任何输入图像的每个位置都要进行计算,它表示每个位置对该类别的重要程度。举例来说,对于输入到猫狗分类卷积神经网络的一张图像,CAM可视化可以生成类别“猫”的热力图,表示图像的各个部分与“猫”的相似程度,CAM可视化也会生成类别“狗”的热力图,表示图像的各个部分与“狗”的相似程度。
我们将使用的具体实现方式是“Grad-CAM: visual explanations from deep networks via gradient-based localization ”这篇论文中描述的方法。这种方法非常简单:给定一张输入图像,对于一个卷积层的输出特征图,用类别相对于通道的梯度对这个特征图中的每个通道进行加权。直观上来看,理解这个技巧的一种方法是,你是用“每个通道对类别的重要程度”对“输入图像对不同通道的激活强度”的空间图进行加权,从而得到了“输入图像对类别的激活强度”的空间图。
我们再次使用预训练的 VGG16网络来演示此方法。
代码清单 5-40 加载带有预训练权重的 VGG16网络

图 5-34显示了两只非洲象的图像(遵守知识共享许可协议),可能是一只母象和它的小象,它们在大草原上漫步。我们将这张图像转换为 VGG16模型能够读取的格式:模型在大小为224×224的图像上进行训练,这些训练图像都根据 keras.applications.vgg16.preprocess_input函数中内置的规则进行预处理。因此,我们需要加载图像,将其大小调整为 224×224,然后将其转换为float32格式的 Numpy张量,并应用这些预处理规则。

图 5-34 非洲象的测试图像
代码清单 5-41 为 VGG16模型预处理一张输入图像

现在你可以在图像上运行预训练的 VGG16网络,并将其预测向量解码为人类可读的格式。
>>> preds = model.predict(x)
>>> print('Predicted:', decode_predictions(preds, top=3)[0])
Predicted:', [(u'n02504458', u'African_elephant', 0.92546833),
(u'n01871265', u'tusker', 0.070257246),
(u'n02504013', u'Indian_elephant', 0.0042589349)]
对这张图像预测的前三个类别分别为:
- 非洲象(African elephant,92.5%的概率)
- 长牙动物(tusker,7%的概率)
- 印度象(Indian elephant,0.4%的概率)
网络识别出图像中包含数量不确定的非洲象。预测向量中被最大激活的元素是对应“非洲象”类别的元素,索引编号为 386。
>>> np.argmax(preds[0]) 386
为了展示图像中哪些部分最像非洲象,我们来使用 Grad-CAM算法。
代码清单 5-42 应用 Grad-CAM算法

为了便于可视化,我们还需要将热力图标准化到 0~1范围内。得到的结果如图 5-35所示。
代码清单 5-43 热力图后处理
heatmap = np.maximum(heatmap, 0) heatmap /= np.max(heatmap) plt.matshow(heatmap)
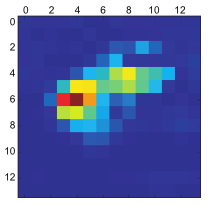
图 5-35 测试图像的“非洲象”类激活热力图
最后,我们可以用 OpenCV来生成一张图像,将原始图像叠加在刚刚得到的热力图上(见图 5-36)。
代码清单 5-44 将热力图与原始图像叠加


图 5-36 将类激活热力图叠加到原始图像上
这种可视化方法回答了两个重要问题:
- 网络为什么会认为这张图像中包含一头非洲象?
- 非洲象在图像中的什么位置?
尤其值得注意的是,小象耳朵的激活强度很大,这可能是网络找到的非洲象和印度象的不同之处。
本章小结
- 卷积神经网络是解决视觉分类问题的最佳工具。
- 卷积神经网络通过学习模块化模式和概念的层次结构来表示视觉世界。
- 卷积神经网络学到的表示很容易可视化,卷积神经网络不是黑盒。
- 现在你能够从头开始训练自己的卷积神经网络来解决图像分类问题。
- 你知道了如何使用视觉数据增强来防止过拟合。
- 你知道了如何使用预训练的卷积神经网络进行特征提取与模型微调。
- 你可以将卷积神经网络学到的过滤器可视化,也可以将类激活热力图可视化。