
8.4 用变分自编码器生成图像
从图像的潜在空间中采样,并创建全新图像或编辑现有图像,这是目前最流行也是最成功的创造性人工智能应用。在本节和下一节中,我们将会介绍一些与图像生成有关的高级概念,还会介绍该领域中两种主要技术的实现细节,这两种技术分别是 变分自编码器(VAE,variational autoencoder)和生成式对抗网络(GAN,generative adversarial network)。我们这里介绍的技术不仅适用于图像,使用 GAN和 VAE还可以探索声音、音乐甚至文本的潜在空间,但在实践中,最有趣的结果都是利用图像获得的,这也是我们这里介绍的重点。
8.4.1 从图像的潜在空间中采样
图像生成的关键思想就是找到一个低维的表示潜在空间(latent space,也是一个向量空间),其中任意点都可以被映射为一张逼真的图像。能够实现这种映射的模块,即以潜在点作为输入并输出一张图像(像素网格),叫作生成器(generator,对于 GAN而言)或解码器(decoder,对于 VAE而言)。一旦找到了这样的潜在空间,就可以从中有意地或随机地对点进行采样,并将其映射到图像空间,从而生成前所未见的图像(见图 8-9)。
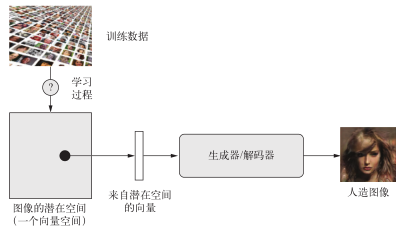
图 8-9 学习图像的潜在向量空间,并利用这个空间来采样新图像
想要学习图像表示的这种潜在空间, GAN和 VAE是两种不同的策略,每种策略都有各自的特点。VAE非常适合用于学习具有良好结构的潜在空间,其中特定方向表示数据中有意义的变化轴(见图 8-10)。GAN生成的图像可能非常逼真,但它的潜在空间可能没有良好结构,也没有足够的连续性。

图 8-10 Tom White使用 VAE生成的人脸连续空间
8.4.2 图像编辑的概念向量
第 6章介绍词嵌入时,我们已经暗示了概念向量(concept vector)的想法:给定一个表示的潜在空间或一个嵌入空间,空间中的特定方向可能表示原始数据中有趣的变化轴。比如在人脸图像的潜在空间中,可能存在一个微笑向量(smile vector)s,它满足:如果潜在点z是某张人脸的嵌入表示,那么潜在点z+s就是同一张人脸面带微笑的嵌入表示。一旦找到了这样的向量,就可以用这种方法来编辑图像:将图像投射到潜在空间中,用一种有意义的方式来移动其表示,然后再将其解码到图像空间。在图像空间中任意独立的变化维度都有概念向量,对于人脸而言,你可能会发现向人脸添加墨镜的向量、去掉墨镜的向量。将男性面孔变成女性面孔的向量等。图 8-11是一个微笑向量的例子,它是由新西兰维多利亚大学设计学院的 Tom White发现的概念向量,使用的是在名人人脸数据集(CelebA数据集)上训练的 VAE。

图 8-11 微笑向量
8.4.3 变分自编码器
自编码器由 Kingma和 Welling于 2013年 12月与 Rezende、Mohamed和 Wierstra于 2014年1月同时发现,它是一种生成式模型,特别适用于利用概念向量进行图像编辑的任务。它是一种现代化的自编码器,将深度学习的想法与贝叶斯推断结合在一起。自编码器是一种网络类型,其目的是将输入编码到低维潜在空间,然后再解码回来。
经典的图像自编码器接收一张图像,通过一个编码器模块将其映射到潜在向量空间,然后再通过一个解码器模块将其解码为与原始图像具有相同尺寸的输出(见图 8-12)。然后,使用与输入图像相同的图像作为目标数据来训练这个自编码器,也就是说,自编码器学习对原始输入进行重新构建。通过对代码(编码器的输出)施加各种限制,我们可以让自编码器学到比较有趣的数据潜在表示。最常见的情况是将代码限制为低维的并且是稀疏的(即大部分元素为 0),在这种情况下,编码器的作用是将输入数据压缩为更少二进制位的信息。
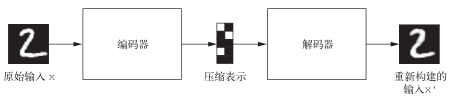
图 8-12 自编码器:将输入x映射为压缩表示,然后再将其解码为x’
在实践中,这种经典的自编码器不会得到特别有用或具有良好结构的潜在空间。它们也没有对数据做多少压缩。因此,它们已经基本上过时了。但是, VAE向自编码器添加了一点统计魔法,迫使其学习连续的、高度结构化的潜在空间。这使得 VAE已成为图像生成的强大工具。
VAE不是将输入图像压缩成潜在空间中的固定编码,而是将图像转换为统计分布的参数,即平均值和方差。本质上来说,这意味着我们假设输入图像是由统计过程生成的,在编码和解码过程中应该考虑这一过程的随机性。然后, VAE使用平均值和方差这两个参数来从分布中随机采样一个元素,并将这个元素解码到原始输入(见图 8-13)。这个过程的随机性提高了其稳健性,并迫使潜在空间的任何位置都对应有意义的表示,即潜在空间采样的每个点都能解码为有效的输出。
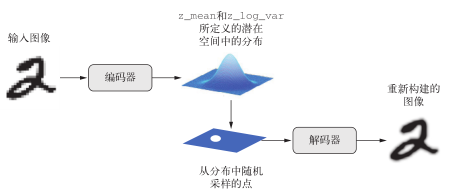
图 8-13 AVE将一张图像映射为两个向量z_mean和z_log_var,二者定义了潜在
空间中的一个概率分布,用于采样一个潜在点并对其进行解码
从技术角度来说,VAE的工作原理如下。
(1)一个编码器模块将输入样本 input_img转换为表示潜在空间中的两个参数 z_mean和z_log_variance。
(2)我们假定潜在正态分布能够生成输入图像,并从这个分布中随机采样一个点 z:z =z_mean + exp(z_log_variance) * epsilon,其中epsilon是取值很小的随机张量。
(3)一个解码器模块将潜在空间的这个点映射回原始输入图像。
因为epsilon是随机的,所以这个过程可以确保,与 input_img编码的潜在位置(即z-mean)靠近的每个点都能被解码为与 input_img类似的图像,从而迫使潜在空间能够连续地有意义。潜在空间中任意两个相邻的点都会被解码为高度相似的图像。连续性以及潜在空间的低维度,将迫使潜在空间中的每个方向都表示数据中一个有意义的变化轴,这使得潜在空间具有非常良好的结构,因此非常适合通过概念向量来进行操作。
VAE的参数通过两个损失函数来进行训练:一个是重构损失(reconstruction loss),它迫使解码后的样本匹配初始输入;另一个是正则化损失(regularization loss),它有助于学习具有良好结构的潜在空间,并可以降低在训练数据上的过拟合。我们来快速浏览一下 Keras实现的VAE。其大致代码如下所示。

然后,你可以使用重构损失和正则化损失来训练模型。
下列代码给出了我们将使用的编码器网络,它将图像映射为潜在空间中概率分布的参数。它是一个简单的卷积神经网络,将输入图像x映射为两个向量z_mean和z_log_var。
代码清单 8-23 VAE编码器网络

接下来的代码将使用z_mean和z_log_var来生成一个潜在空间点z,z_mean和z_log_var是统计分布的参数,我们假设这个分布能够生成 input_img。这里,我们将一些随意的代码(这些代码构建于 Keras后端之上)包装到Lambda层中。在 Keras中,任何对象都应该是一个层,所以如果代码不是内置层的一部分,我们应该将其包装到一个Lambda层(或自定义层)中。
代码清单 8-24 潜在空间采样的函数
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim),
mean=0., stddev=1.)
return z_mean + K.exp(z_log_var) * epsilon
z = layers.Lambda(sampling)([z_mean, z_log_var])
下列代码给出了解码器的实现。我们将向量 z的尺寸调整为图像大小,然后使用几个卷积层来得到最终的图像输出,它和原始图像input_img具有相同的大小。
代码清单 8-25 VAE解码器网络,将潜在空间点映射为图像

我们一般认为采样函数的形式为 loss(input, target),VAE的双重损失不符合这种形式。因此,损失的设置方法为:编写一个自定义层,并在其内部使用内置的 add_loss层方法来创建一个你想要的损失。
代码清单 8-26 用于计算 VAE损失的自定义层


最后,将模型实例化并开始训练。因为损失包含在自定义层中,所以在编译时无须指定外部损失(即loss=None),这意味着在训练过程中不需要传入目标数据。(如你所见,我们在调用fit时只向模型传入了x_train。)
代码清单 8-27 训练 VAE
from keras.datasets import mnist
vae = Model(input_img, y)
vae.compile(optimizer='rmsprop', loss=None)
vae.summary()
(x_train, _), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_train = x_train.reshape(x_train.shape + (1,))
x_test = x_test.astype('float32') / 255.
x_test = x_test.reshape(x_test.shape + (1,))
vae.fit(x=x_train, y=None,
shuffle=True,
epochs=10,
batch_size=batch_size,
validation_data=(x_test, None))
一旦训练好了这样的模型(本例中是在 MNIST上训练),我们就可以使用decoder网络将任意潜在空间向量转换为图像。
代码清单 8-28 从二维潜在空间中采样一组点的网格,并将其解码为图像


采样数字的网格(见图 8-14)展示了不同数字类别的完全连续分布:当你沿着潜在空间的一条路径观察时,你会观察到一个数字逐渐变形为另一个数字。这个空间的特定方向具有一定的意义,比如,有一个方向表示“逐渐变为 4”、有一个方向表示“逐渐变为 1”等。
下一节我们将会详细介绍生成人造图像的另一个重要工具,即生成式对抗网络(GAN)。

图 8-14 从潜在空间解码得到的数字网格
8.4.4 小结
- 用深度学习进行图像生成,就是通过对潜在空间进行学习来实现的,这个潜在空间能够捕捉到关于图像数据集的统计信息。通过对潜在空间中的点进行采样和解码,我们可以生成前所未见的图像。这种方法有两种重要工具:变分自编码器( VAE)和生成式对抗网络(GAN)。
- VAE得到的是高度结构化的、连续的潜在表示。因此,它在潜在空间中进行各种图像编辑的效果很好,比如换脸、将皱眉脸换成微笑脸等。它制作基于潜在空间的动画效果也很好,比如沿着潜在空间的一个横截面移动,从而以连续的方式显示从一张起始图像缓慢变化为不同图像的效果。
- GAN可以生成逼真的单幅图像,但得到的潜在空间可能没有良好的结构,也没有很好的连续性。
对于图像,我见过的大多数成功的实际应用都是依赖于 VAE的,但 GAN在学术研究领域非常流行,至少在 2016—2017年左右是这样。下一节将会介绍 GAN的工作原理以及实现。
提示
如果你想进一步研究图像生成,我建议你使用大规模名人人脸属性( CelebA)数据集。它是一个可以免费下载的图像数据集,里面包含超过 20万张名人肖像,特别适合用概念向量进行实验,其结果肯定能打败 MNIST。