8.5 生成式对抗网络简介
生成式对抗网络(GAN,generative adversarial network)由 Goodfellow等人于 2014年提出,它可以替代 VAE来学习图像的潜在空间。它能够迫使生成图像与真实图像在统计上几乎无法区分,从而生成相当逼真的合成图像。
对 GAN的一种直观理解是,想象一名伪造者试图伪造一副毕加索的画作。一开始,伪造者非常不擅长这项任务。他将自己的一些赝品与毕加索真迹混在一起,并将其展示给一位艺术商人。艺术商人对每幅画进行真实性评估,并向伪造者给出反馈,告诉他是什么让毕加索作品看起来像一幅毕加索作品。伪造者回到自己的工作室,并准备一些新的赝品。随着时间的推移,伪造者变得越来越擅长模仿毕加索的风格,艺术商人也变得越来越擅长找出赝品。最后,他们手上拥有了一些优秀的毕加索赝品。
这就是 GAN的工作原理:一个伪造者网络和一个专家网络,二者训练的目的都是为了打败彼此。因此,GAN由以下两部分组成。
- 生成器网络(generator network):它以一个随机向量(潜在空间中的一个随机点)作为输入,并将其解码为一张合成图像。
- 判别器网络(discriminator network)或对手(adversary):以一张图像(真实的或合成的均可)作为输入,并预测该图像是来自训练集还是由生成器网络创建。
训练生成器网络的目的是使其能够欺骗判别器网络,因此随着训练的进行,它能够逐渐生成越来越逼真的图像,即看起来与真实图像无法区分的人造图像,以至于判别器网络无法区分二者(见图 8-15)。与此同时,判别器也在不断适应生成器逐渐提高的能力,为生成图像的真实性设置了很高的标准。一旦训练结束,生成器就能够将其输入空间中的任何点转换为一张可信图像(见图 8-16)。与 VAE不同,这个潜在空间无法保证具有有意义的结构,而且它还是不连续的。
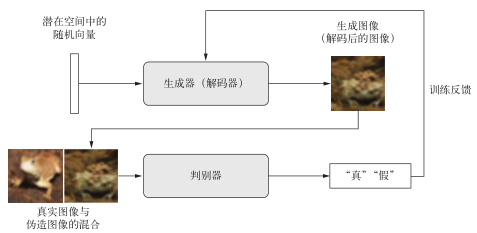
图 8-15 生成器将随机潜在向量转换成图像,判别器试图分辨真实图像与生成图像。生成器的训练是为了欺骗判别器
值得注意的是,GAN这个系统与本书中其他任何训练方法都不同,它的优化最小值是不固定的。通常来说,梯度下降是沿着静态的损失地形滚下山坡。但对于 GAN而言,每下山一步,都会对整个地形造成一点改变。它是一个动态的系统,其最优化过程寻找的不是一个最小值,而是两股力量之间的平衡。因此, GAN的训练极其困难,想要让 GAN正常运行,需要对模型架构和训练参数进行大量的仔细调整。

图 8-16 潜在空间的“居民”。Mike Tyka利用在人脸数据集上训练的多级 GAN所生成的图像
8.5.1 GAN的简要实现流程
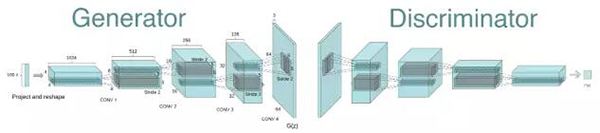
本节将会介绍如何用 Keras来实现形式最简单的 GAN。GAN属于高级应用,所以本书不会深入介绍其技术细节。我们具体实现的是一个深度卷积生成式对抗网络(DCGAN,deep convolutional GAN),即生成器和判别器都是深度卷积神经网络的 GAN。特别地,它在生成器中使用Conv2DTranspose层进行图像上采样。
我们将在 CIFAR10数据集的图像上训练 GAN,这个数据集包含 50 000张 32×32的 RGB图像,这些图像属于 10个类别(每个类别 5000张图像)。为了简化,我们只使用属于“frog”(青蛙)类别的图像。
GAN的简要实现流程如下所示。
(1) generator网络将形状为(latent_dim,)的向量映射到形状为(32, 32, 3)的图像。
(2) discriminator网络将形状为(32, 32, 3)的图像映射到一个二进制分数,用于评估图像为真的概率。
(3) gan网络将generator网络和discriminator网络连接在一起:gan(x) = discriminator(generator(x))。生成器将潜在空间向量解码为图像,判别器对这些图像的真实性进行评估,因此这个gan网络是将这些潜在向量映射到判别器的评估结果。
(4)我们使用带有“真”/“假”标签的真假图像样本来训练判别器,就和训练普通的图像分类模型一样。
(5)为了训练生成器,我们要使用 gan模型的损失相对于生成器权重的梯度。这意味着,在每一步都要移动生成器的权重,其移动方向是让判别器更有可能将生成器解码的图像划分为“真”。换句话说,我们训练生成器来欺骗判别器。
8.5.2 大量技巧
训练 GAN和调节 GAN实现的过程非常困难。你应该记住一些公认的技巧。与深度学习中的大部分内容一样,这些技巧更像是炼金术而不是科学,它们是启发式的指南,并没有理论上的支持。这些技巧得到了一定程度的来自对现象的直观理解的支持,经验告诉我们,它们的效果都很好,但不一定适用于所有情况。
下面是本节实现 GAN生成器和判别器时用到的一些技巧。这里并没有列出与 GAN相关的全部技巧,更多技巧可查阅关于 GAN的文献。
- 我们使用tanh作为生成器最后一层的激活,而不用sigmoid,后者在其他类型的模型中更加常见。
- 我们使用正态分布(高斯分布)对潜在空间中的点进行采样,而不用均匀分布。
- 随机性能够提高稳健性。训练GAN得到的是一个动态平衡,所以GAN可能以各种方式“卡住”。在训练过程中引入随机性有助于防止出现这种情况。我们通过两种方式引入随机性: 一种是在判别器中使用 dropout,另一种是向判别器的标签添加随机噪声。
- 稀疏的梯度会妨碍 GAN的训练。在深度学习中,稀疏性通常是我们需要的属性,但在GAN中并非如此。有两件事情可能导致梯度稀疏:最大池化运算和 ReLU激活。我们推荐使用步进卷积代替最大池化来进行下采样,还推荐使用LeakyReLU层来代替ReLU激活。LeakyReLU和ReLU类似,但它允许较小的负数激活值,从而放宽了稀疏性限制。
- 在生成的图像中,经常会见到棋盘状伪影,这是由生成器中像素空间的不均匀覆盖导致的(见图 8-17)。为了解决这个问题,每当在生成器和判别器中都使用步进的Conv2DTranpose或Conv2D时,使用的内核大小要能够被步幅大小整除。

图 8-17 由于步幅大小和内核大小不匹配而导致的棋盘状伪影,进而导致像素空间不均匀的覆盖;这是 GAN的诸多陷阱之一
8.5.3 生成器
首先,我们来开发generator模型,它将一个向量(来自潜在空间,训练过程中对其随机采样)转换为一张候选图像。GAN常见的诸多问题之一,就是生成器“卡在”看似噪声的生成图像上。一种可行的解决方案是在判别器和生成器中都使用 dropout。
代码清单 8-29 GAN生成器网络

8.5.4 判别器
接下来,我们来开发 discriminator模型,它接收一张候选图像(真实的或合成的)作为输入,并将其划分到这两个类别之一:“生成图像”或“来自训练集的真实图像”。
代码清单 8-30 GAN判别器网络

8.5.5 对抗网络
最后,我们要设置 GAN,将生成器和判别器连接在一起。训练时,这个模型将让生成器向某个方向移动,从而提高它欺骗判别器的能力。这个模型将潜在空间的点转换为一个分类决策(即“真”或“假”),它训练的标签都是“真实图像”。因此,训练gan将会更新generator的权重,使得discriminator在观察假图像时更有可能预测为“真”。请注意,有一点很重要,就是在训练过程中需要将判别器设置为冻结(即不可训练),这样在训练gan时它的权重才不会更新。如果在此过程中可以对判别器的权重进行更新,那么我们就是在训练判别器始终预测“真”,但这并不是我们想要的!
代码清单 8-31 对抗网络

8.5.6 如何训练 DCGAN
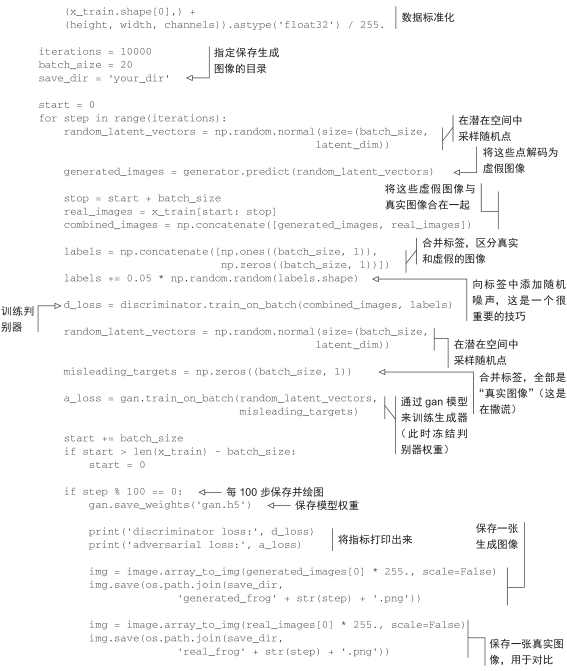
现在开始训练。再次强调一下,训练循环的大致流程如下所示。每轮都进行以下操作。
(1)从潜在空间中抽取随机的点(随机噪声)。
(2)利用这个随机噪声用generator生成图像。
(3)将生成图像与真实图像混合。
(4)使用这些混合后的图像以及相应的标签(真实图像为“真”,生成图像为“假”)来训练discriminator,如图 8-18所示。
(5)在潜在空间中随机抽取新的点。
(6)使用这些随机向量以及全部是“真实图像”的标签来训练gan。这会更新生成器的权重(只更新生成器的权重,因为判别器在 gan中被冻结),其更新方向是使得判别器能够将生成图像预测为“真实图像”。这个过程是训练生成器去欺骗判别器。
我们来实现这一流程。

图 8-18 假设你是判别器:在每一列中,有两张图像是由 GAN生成的,一张图像来自训练集。你能区分出来吗(答案:每一列的真实图像分别位于中、上、下、中)
代码清单 8-32 实现 GAN的训练

训练时你可能会看到,对抗损失开始大幅增加,而判别损失则趋向于零,即判别器最终支配了生成器。如果出现了这种情况,你可以尝试减小判别器的学习率,并增大判别器的 dropout比率。
8.5.7 小结
- GAN由一个生成器网络和一个判别器网络组成。判别器的训练目的是能够区分生成器的输出与来自训练集的真实图像,生成器的训练目的是欺骗判别器。值得注意的是,生成器从未直接见过训练集中的图像,它所知道的关于数据的信息都来自于判别器。
- GAN很难训练,因为训练 GAN是一个动态过程,而不是具有固定损失的简单梯度下降过程。想要正确地训练 GAN,需要使用一些启发式技巧,还需要大量的调节。
- GAN可能会生成非常逼真的图像。但与 VAE不同,GAN学习的潜在空间没有整齐的连续结构,因此可能不适用于某些实际应用,比如通过潜在空间概念向量进行图像编辑。
本章总结
- 借助深度学习的创造性应用,深度网络不仅能够对现有内容进行标注,还能够自己生成新内容。本章我们学到的内容如下。
- 如何生成序列数据,每次生成一个时间步。这可以应用于文本生成,也可应用于逐个音符的音乐生成或其他任何类型的时间序列数据。
- DeepDream的工作原理:通过输入空间中的梯度上升将卷积神经网络的层激活最大化。
- 如何实现风格迁移,即将内容图像和风格图像组合在一起,并产生有趣的效果。
- 什么是对抗式生成网络(GAN),什么是变分自编码器(VAE),它们如何用于创造新图像,以及如何使用潜在空间概念向量进行图像编辑。
- 这几项技术仅涉及了这一快速发展领域的基础知识,还有许多内容等待你去探索。仅生成式深度学习这一领域的内容就可以写一整本书。